La classificazione di una nuvola LIDAR non è più un optional
La classificazione è il processo che definisce per ogni punto di una nuvola la sua natura. È un'operazione fondamentale e necessaria quando si lavora con dati LiDAR e si vuole ottenere l'informazione del solo terreno.

Hai ricevuto i dati di un rilievo LiDAR.
Apri il file, carichi la nuvola di punti, e ti trovi davanti milioni di punti colorati che rappresentano tutto ciò che il sensore ha visto: alberi, terreno, strade, edifici...
Il dato è denso, accurato, georeferenziato.
Ma non sai cosa fartene.
Non perché manchi la competenza ma perché quel dato non è stato preparato per essere usato.
È stato acquisito, processato e consegnato così com'è: grezzo.
E in quella forma, per la maggior parte dei committenti, non è utile.
Questo articolo parla di classificazione della nuvola di punti LiDAR: cos'è, perché è necessaria, cosa si ottiene quando viene fatta bene e cosa succede quando non viene fatta affatto.


Il LiDAR si è democratizzato, il workflow no
Fino a qualche anno fa, i sensori LiDAR erano strumenti costosi e accessibili solo a pochi operatori specializzati.
Oggi la situazione è cambiata in modo significativo: i prezzi sono scesi e il numero di operatori che offre rilievi LiDAR è cresciuto.
Questo è un bene.
Significa che la tecnologia raggiunge più contesti, più committenti, più problemi da risolvere.
C'è però un aspetto che non sta tenendo il passo: la cultura del dato.
Acquisire una nuvola di punti con un sensore LiDAR è diventato "relativamente" semplice.
Restituire un dato classificato, pronto all'uso, richiede competenza aggiuntiva e tempo di elaborazione e, a volte, viene saltato.
Il risultato è che si moltiplicano i rilievi LiDAR il cui output finale è una nuvola grezza.
Tecnicamente valida.
Praticamente difficile da usare.
Cosa succede quando il dato non viene classificato
Il committente — uno studio di progettazione, un'amministrazione pubblica, un'impresa — riceve la nuvola, la apre nel suo software (ammesso che ne abbia uno) e si trova davanti una massa di punti indistinta.
Vegetazione e terreno sono insieme.
Non riesce a estrarre il modello del suolo.
Non sa dove si trova un sentiero o un strada mappati su una CTR.
Dopo una o due esperienze così il rischio concreto è che smetta di richiedere il LiDAR.
Non perché la tecnologia non funzioni ma perché non ha mai visto cosa può fare quando il dato viene elaborato correttamente.
Per lui, il dato LiDAR è complicato, costoso da gestire e con risultati difficili da interpretare.
Questo meccanismo frena la diffusione della tecnologia più efficacemente di qualsiasi barriera di prezzo.
È un problema di settore e di cultura.




Cos'è la classificazione della nuvola di punti
La classificazione è il processo attraverso cui si assegna a ogni punto della nuvola una categoria semantica: terreno, vegetazione bassa, vegetazione alta, edifici, sovrastrutture, rumore.
A ogni classe viene assegnato un codice — lo standard più diffuso è quello definito dall'ISPRS — e da quel momento in poi i punti sono interrogabili separatamente.
Vuoi solo il terreno? Filtri la classe "ground" e ottieni il modello digitale del terreno (DTM).
Vuoi la vegetazione alta? Filtri la classe corrispondente e puoi analizzare copertura, altezza, densità. Vuoi tutto tranne il rumore? Escludi la classe dedicata e la nuvola è pulita.
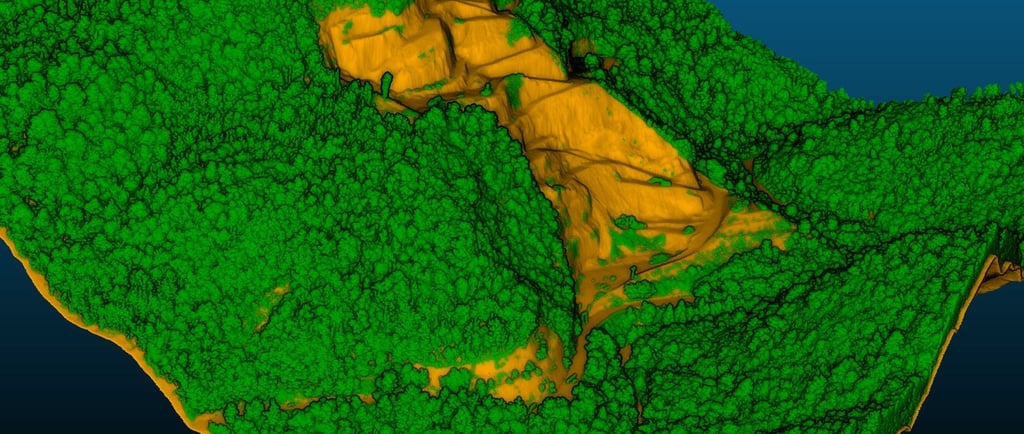
In un contesto come quello di questo rilievo — un'area di cava con ampie zone boscate — la classificazione è ciò che permette di separare i milioni di punti che rappresentano alberi e arbusti dai punti che rappresentano il suolo reale.



Il sensore fa la differenza: ecco perché
Non tutti i sensori LiDAR sono uguali rispetto alla capacità di rilevare il terreno sotto la vegetazione.
Il parametro che conta si chiama capacità multi-ritorno (o multi-echo).
Ogni impulso laser inviato dal sensore può tornare più volte: la prima riflessione arriva dalla chioma dell'albero (primo ritorno), le successive penetrano progressivamente fino a raggiungere il suolo (ultimi ritorni).
Un sensore che registra solo il primo ritorno vede solo la vegetazione.
Un sensore multi-ritorno può catturare anche l'informazione del suolo, anche in presenza di copertura arborea.
Questo non è un dettaglio tecnico secondario: è la condizione necessaria perché la classificazione possa produrre un DTM affidabile sotto la vegetazione.
Se il sensore usato per il rilievo non ha questa caratteristica, la classificazione potrà separare le classi evidenti, ma il terreno sotto la chioma rimarrà poco rappresentato — e quindi il DTM sarà parziale o inaffidabile proprio nelle zone che interessano di più.
Ne avevo parlato in un video.
Lo trovi qui sotto

La stagione non è un dettaglio
C'è un altro fattore che influenza significativamente la qualità del dato LiDAR in contesti vegetati: il periodo dell'anno in cui viene eseguito il rilievo.
In inverno o a inizio primavera — prima che la vegetazione abbia ripreso le foglie — la chioma è molto meno densa.
Gli impulsi laser penetrano più facilmente, il numero di punti che raggiunge il suolo aumenta, e la classificazione del terreno risulta più pulita e più completa.
In piena estate, con la vegetazione in piena attività, la chioma è densa e l'attenuazione degli impulsi è massima. Non impossibile da classificare, ma più difficile e con un DTM finale meno ricco nelle zone più boscate.
Per questo i rilievi LiDAR in contesti forestali o semi-forestati andrebbero pianificati tenendo conto della stagione.
Non è sempre possibile scegliere, ma quando si può è una variabile che vale la pena considerare.




Il software aiuta ma spesso non basta.
Esistono algoritmi di classificazione automatica integrati in alcuni software di elaborazione di nuvole di punti.
Alcuni producono risultati interessanti su terreni aperti, con poca vegetazione e morfologia regolare.
O riescono comunque a fare una "sgrossatura" dell'informazione.
In contesti complessi — zone di transizione tra vegetazione e terreno nudo, scarpate, fronti di cava, ambiti urbani — gli algoritmi automatici tendono a fare errori o a lasciare indietro un po' di cose. Classificano come terreno punti che sono in realtà arbusti bassi.
Non riconoscono elementi.
Assegnano alla classe "rumore" punti che invece appartengono a strutture reali.
In questi casi il tecnico deve intervenire manualmente: revisionare la classificazione automatica, correggere le classi errate, integrare con analisi visiva della nuvola.
È un lavoro che richiede esperienza, strumenti adeguati e tempo.
Non è un fallimento degli algoritmi è semplicemente il limite di qualsiasi approccio automatico applicato a dati complessi.
Cosa emerge dalla nuvola classificata: il caso di questa cava
In questo rilievo, l'area di interesse comprende sia le zone attive della cava — fronti rocciosi, piazzali, strade di accesso — sia zone boscate ai margini e tra i livelli di coltivazione.
Guardando le foto aeree, quelle zone vegetate sono semplicemente "verde".
Non c'è altro da leggere.
Sentieri, strade secondarie, piccole morfologie del terreno: è tutto nascosto dalla chioma.
Dalla nuvola classificata, invece, emerge un DTM che racconta una storia diversa.
I tracciati stradali sotto la vegetazione diventano visibili.
La morfologia del terreno — pendenze, impluvi, scarpate — è leggibile anche dove la fotogrammetria non arriverebbe mai, perché la copertura vegetale impedirebbe qualsiasi lettura del suolo.
Questo è il valore concreto del LiDAR rispetto ad altri metodi di rilievo: non la nuvola colorata in sé, ma l'informazione che quella nuvola — classificata — permette di estrarre.




Cosa chiedere quando commissioni un rilievo LiDAR
Se ti trovi dalla parte del committente — stai valutando un rilievo LiDAR per un progetto, una verifica, un'analisi di territorio — c'è una cosa concreta che puoi fare per non ritrovarti con un dato inutilizzabile.
Chiedilo esplicitamente nel capitolato o nell'accordo di fornitura: la nuvola di punti classificata è parte del "deliverable".
Non un optional, non un "si può fare se volete".
Una condizione standard.
Specifica le classi che ti servono: terreno, vegetazione alta, vegetazione bassa, edifici, eventualmente strade o infrastrutture.
Specifica il formato di consegna (LAS/LAZ con classificazione ISPRS standard).
E se il contesto prevede vegetazione significativa, chiedi conferma che il sensore usato sia multi-ritorno.
Non è una richiesta tecnica eccessiva.
È chiedere un dato finito, non un dato ancora grezzo.
La responsabilità è del tecnico che esegue il rilievo
Ultimo punto, e forse il più importante.
La classificazione della nuvola di punti non è un servizio aggiuntivo che il committente deve richiedere espressamente.
Dovrebbe essere parte integrante di un rilievo LiDAR così come la georeferenziazione è parte di qualsiasi rilievo, non un extra.
Chi esegue il rilievo conosce il contesto, ha accesso ai dati grezzi, ha gli strumenti per classificarli.
Il committente — spesso un tecnico di altro profilo, o un'amministrazione, o un'impresa — non ha nessuna di queste cose.
Se il dato viene consegnato grezzo, il problema non è del committente che non sa usarlo.
È di chi lo ha consegnato senza completare il lavoro.
Normalizzare la classificazione come standard del "deliverable" è nell'interesse di tutti: del committente, che riceve un dato utilizzabile; del tecnico, che dimostra competenza e affidabilità; e del settore nel suo insieme, che può crescere solo se i committenti capiscono cosa il LiDAR è capace di fare.


www.3dmetrica.it © 2026
3DMetrica di Ing. Paolo Corradeghini
Via Bertoloni, 59 - 19038 - Sarzana (SP)
PIVA 01260880115
email paolo.corradeghini@3dmetrica.it
pec paolo.corradeghini@pec.it
Ai sensi delle disposizioni in merito a pubblicità e trasparenza su contributi e finanziamenti, comunico di aver beneficiato di quanto segue:
Soggetto erogatore: FILSE - Finanziaria ligure per lo sviluppo economico - Oggetto: Bando per la digitalizzazione delle micro, piccole e medie imprese - Anno: 2024 - Somma: 15.045,73 € - Impiego: Sistema SLAM Emesent Hovermap ST
Soggetto erogatore: FILSE - Finanziaria ligure per lo sviluppo economico - Oggetto: Bando per la digitalizzazione delle micro, piccole e medie imprese - Anno: 2022 - Somma: 9.727,20 € - Impiego: DJI Phantom 4 RTK, Trimble Real Works, InstaPro2
Soggetto erogatore: FILSE - Finanziaria ligure per lo sviluppo economico - Oggetto: Bando per la digitalizzazione delle micro, piccole e medie imprese - Anno: 2021 - Somma: 4.772,40 € - Impiego: Workstation Desktop, Workstation Laptop